
Negli ultimi mesi AnythingLLM è diventato uno dei progetti più interessanti per chi vuole usare l’intelligenza artificiale in locale con un approccio pratico, self-hosted e relativamente semplice da gestire. Il motivo è che non si presenta come un semplice frontend per modelli LLM, ma come una piattaforma più completa, pensata per workspace, documenti, modelli locali e agenti AI.
AnythingLLM può essere avviato in locale con Docker su http://localhost:3001, con persistenza dei dati tramite mount della directory /app/server/storage. Inoltre supporta diversi provider LLM locali, tra cui Ollama, LM Studio, Local AI e KoboldCPP, oltre a modelli cloud configurabili nello stesso ambiente.
In questa guida vedremo come installare AnythingLLM in locale, accedere all’interfaccia web e configurare i primi elementi essenziali per iniziare a usarlo davvero.
Cos’è AnythingLLM
AnythingLLM è una piattaforma AI self-hosted pensata per lavorare con modelli linguistici, documenti, workspace e agenti AI. Consente di usare più LLM contemporaneamente e distingue tra System LLM, Workspace LLM e Agent LLM, cioè modelli predefiniti di sistema, modelli specifici per singolo workspace e modelli dedicati agli agenti.
Questo approccio è molto comodo perché permette di usare la stessa applicazione sia come chat AI generica, sia come base per progetti più specifici, per esempio consultazione documentale o workspace separati per compiti diversi.
Perché usarlo in locale
Installare AnythingLLM in locale ha diversi vantaggi, soprattutto se ti interessa la privacy o vuoi un ambiente completamente sotto il tuo controllo.
- Puoi usare modelli locali senza inviare tutto a servizi esterni.
- Puoi creare workspace separati per documenti e contesti diversi.
- Puoi sperimentare con agenti e knowledge base in un ambiente self-hosted.
- AnythingLLM permette di collegare sia LLM locali sia cloud-based nella stessa applicazione.
- Puoi far fare delle ricerche sul web ai modelli LLM in locale, sfruttando gli agenti che usano per esempio DuckDuckGo.
Requisiti minimi
Per seguire questa guida ti consiglio almeno:
- un PC Linux, mini server o VPS con Docker installato;
- accesso al terminale;
- un browser moderno;
- facoltativamente un provider locale già pronto, come Ollama o LM Studio, se vuoi evitare API cloud.
Se vuoi invece usare AnythingLLM come app desktop su Linux, esiste anche una versione AppImage per architetture x64 e arm64, con script di installazione dedicato.
Installare AnythingLLM con Docker
Per la maggior parte degli utenti, il metodo più semplice è Docker. Devi scaricare l’immagine mintplexlabs/anythingllm:latest e ricordare che senza il mount persistente dei dati perderai tutto al riavvio del container.
Per prima cosa scarichiamo l’immagine docker di AnythingLLM:
docker pull mintplexlabs/anythingllm:latestOra creiamo una directory locale per i dati persistenti. Qui verranno salvati tutti i dati di questa piattaforma self-hosted:
mkdir -p ~/anythingllm-storageAvviamo poi il container con:
docker run -d \
-p 3001:3001 \
-e STORAGE_DIR=/app/server/storage \
-v ~/anythingllm-storage:/app/server/storage \
mintplexlabs/anythingllm:latestIl mount verso /app/server/storage è obbligatorio per mantenere dati e progressi tra riavvii o ricreazioni del container Docker.
Primo accesso all’interfaccia web
Dopo l’avvio del container, apri il browser e vai su:
http://localhost:3001Se stai lavorando su un VPS remoto, sostituisci localhost con l’indirizzo IP del server.

Persistenza dei dati – Attenzione!
Questo è uno dei punti più importanti. Se non usi il mount corretto per la cartella storage, tutti i dati andranno persi al riavvio del container.
Per questo motivo conviene sempre usare una directory dedicata sul sistema host e non limitarsi a eseguire un container “al volo” senza volume persistente. Se hai avviato il container docker senza specificare una cartella di cui effettuare il mount sul container, ti consigliamo di fermarlo e rilanciarlo, specificandola.
Possibili problemi di permessi
UID e GID sono impostati a 1000 per impostazione predefinita e eventuali differenze tra utente host e utente del container possono causare problemi di permessi.
Se noti comportamenti strani sulla scrittura dei dati, controlla i permessi della directory montata e verifica che l’utente del sistema host possa leggerla e scriverla correttamente. Normalmente, “1000” è il primo utente normale (non amministratore) su un sistema GNU/Linux, conseguentemente, salvo particolari setup, non dovresti avere problemi.
Configurare il provider LLM
Una volta dentro l’interfaccia, uno dei primi passaggi da fare è configurare il modello LLM che AnythingLLM dovrà usare. Esistono tre livelli:
- System LLM, cioè il modello predefinito globale;
- Workspace LLM, cioè un modello specifico per un singolo workspace;
- Agent LLM, cioè il modello dedicato agli agenti AI.
Questo significa che puoi iniziare con una configurazione semplice e poi specializzare i modelli in base al contesto. Per esempio, potresti usare un modello generico a livello di sistema e un modello differente per un workspace documentale.
Provider locali supportati
AnythingLLM supporta diversi provider locali già integrati:
- Ollama;
- LM Studio;
- Local AI;
- KoboldCPP.
Questa è una caratteristica molto interessante perché ti permette di usare l’applicazione in locale anche senza dipendere da OpenAI o da altri provider cloud.
Se hai il firewall attivo in locale, ad esempio UFW, la connettività con i container docker sarà molto probabilmente limitata. Ti consigliamo di aggiungere delle regole ad-hoc per permettere il traffico tra la rete di Docker e la macchina host, ad esempio se Docker utilizza la rete 172.17.0.0/16, la tua macchina host avrà IP 172.17.0.1 e quindi il comando diventa:
sudo ufw allow in on docker0 from 172.17.0.0/16 to 172.17.0.1
Per sicurezza, verifica quale subnet sta utilizzando docker con il comando:
ip a
Dovrebbe uscire qualcosa del genere:
... 8: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default link/ether a6:a5:df:72:91:c0 brd ff:ff:ff:ff:ff:ff inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0 valid_lft forever preferred_lft forever inet6 fe80::a4a5:dfff:fe72:91c0/64 scope link valid_lft forever preferred_lft forever ...
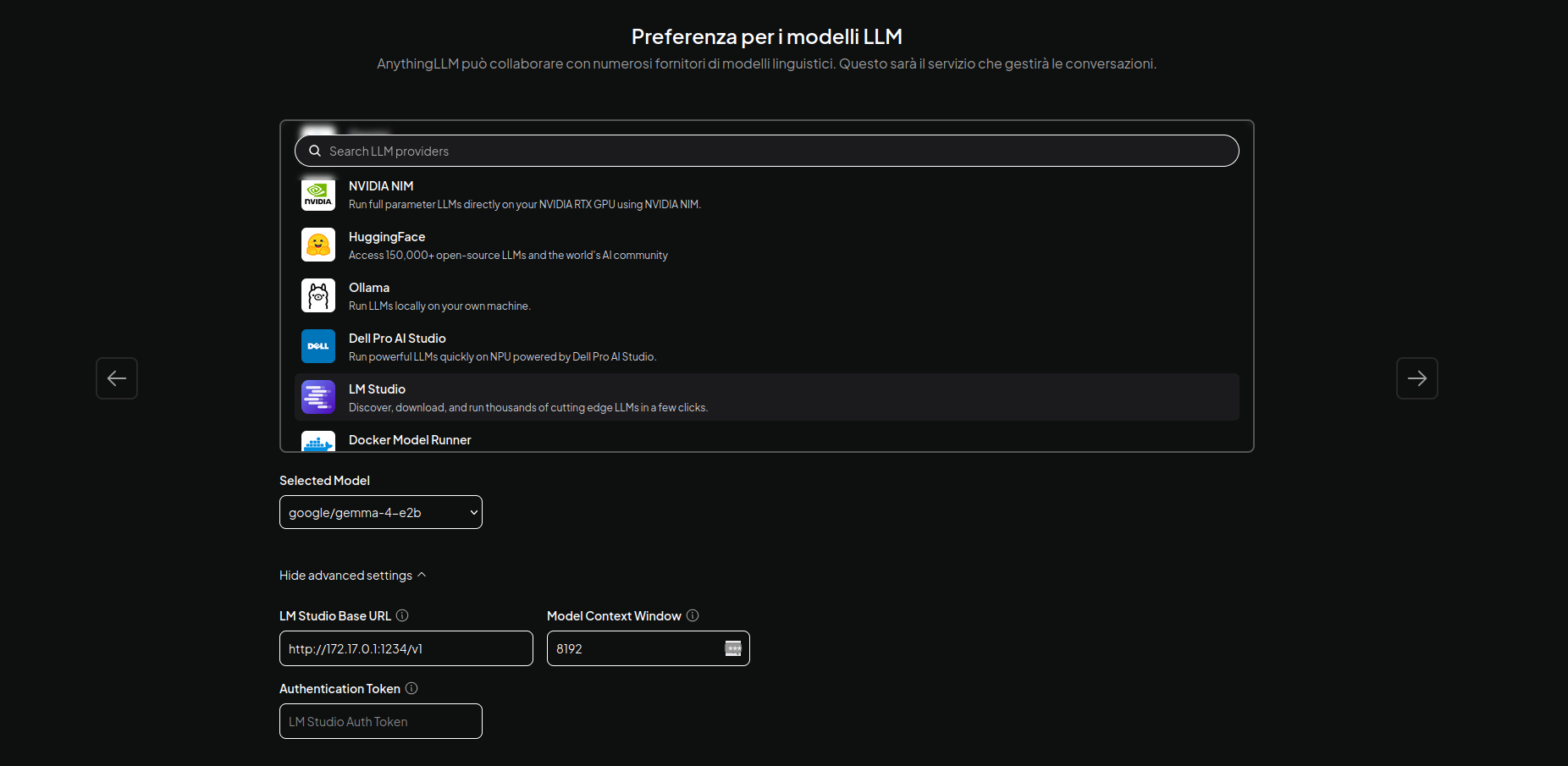
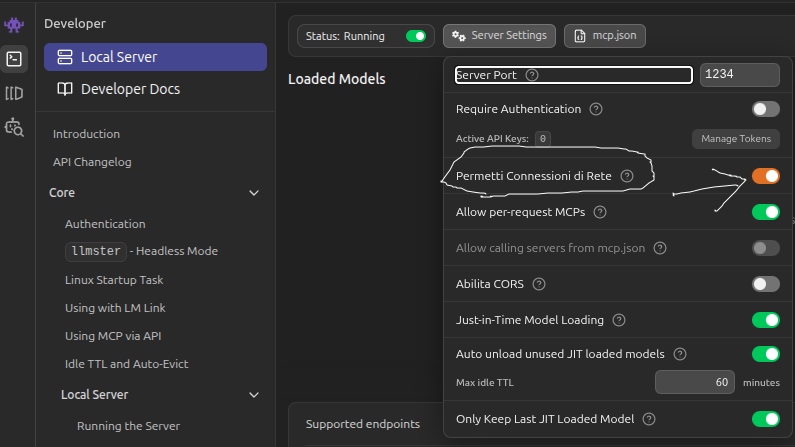
Importante: per LM Studio con Docker
Su LM Studio con Docker, assicurati di aver abilitato la modalità Developer, di avviare il Local Server e di abilitare le connessioni di rete, come mostrato qui, soprattutto se lo usi in LAN. In questo modo non dovrebbero esserci problemi con Docker e con la sua gestione di rete:
Creare il primo workspace
Dopo aver configurato il provider LLM, puoi creare il tuo primo workspace. Il concetto di workspace è centrale in AnythingLLM perché ti consente di separare conversazioni, documenti e impostazioni a seconda dell’uso che vuoi farne.
Un buon primo test è creare un workspace dedicato a un argomento preciso, per esempio “Documentazione tecnica”, “Appunti personali” oppure “Server Linux”.
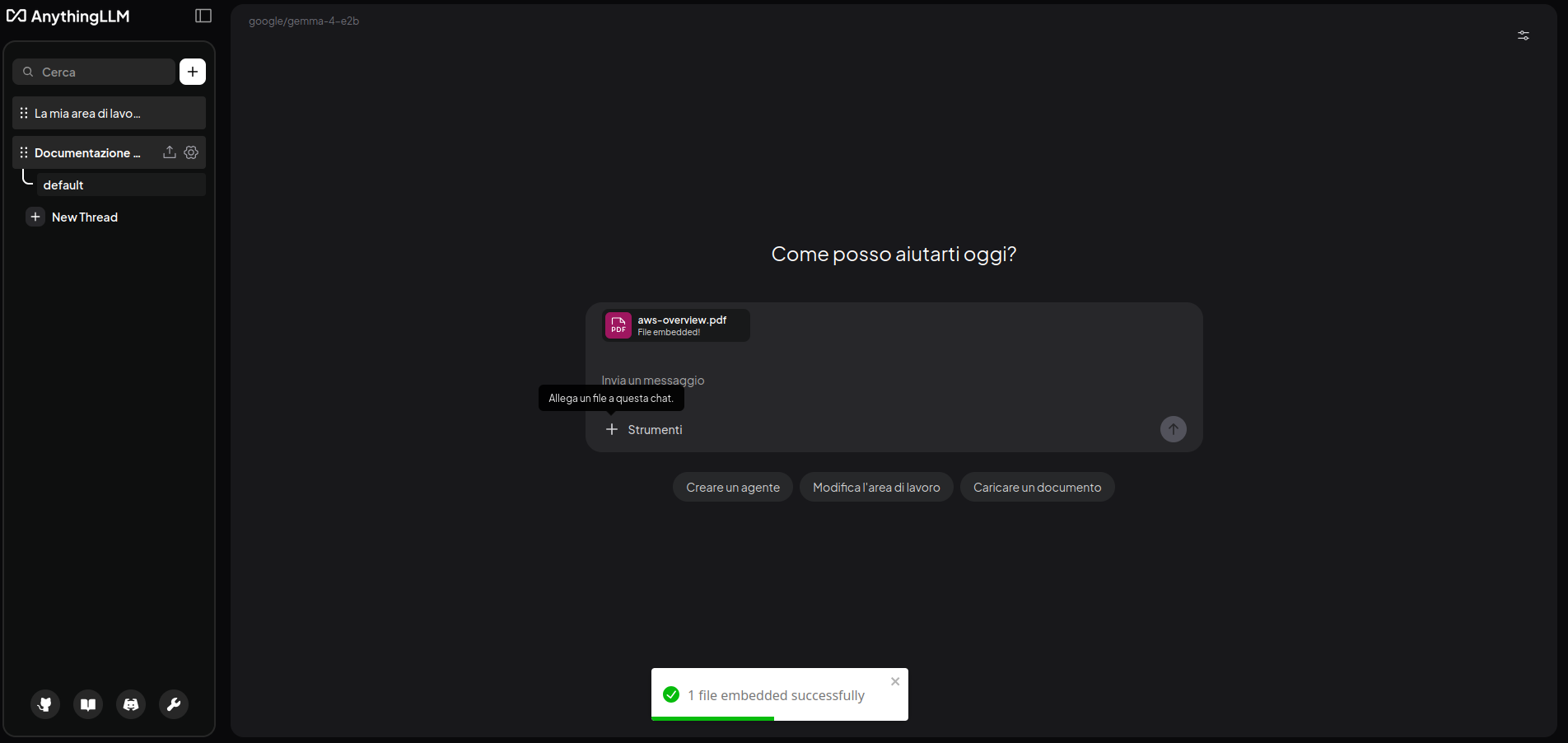
Caricare documenti e costruire una piccola knowledge base
Una delle funzioni più interessanti di AnythingLLM è la possibilità di associare documenti al workspace e poi interrogarli tramite chat. È considerato un buon punto di ingresso al mondo del RAG (Retrieval-Augmented Generation), cioè la tecnica che combina recupero di informazioni rilevanti dai documenti con la generazione di risposte contestualizzate da parte del modello AI.
Per iniziare, carica uno o più documenti semplici nel workspace e poi prova a fare domande specifiche sul contenuto. Questo è il modo migliore per capire se la pipeline di indicizzazione e recupero del contesto sta funzionando correttamente.
Attenzione: se il file caricato (o i file caricati) superano la dimensione della finestra di contesto (Context Window) relativa al LLM selezionato, vi verrà chiesto di effettuare il Text Embedding. È una procedura totalmente automatizzata e gestita da AnythingLLM. Per maggiori informazioni, controlla la documentazione.
Test pratico iniziale
Dopo aver creato il workspace e collegato un modello, puoi fare una prova molto semplice con una domanda come:
Riassumi i punti principali di questi documentiOppure, se hai caricato materiale tecnico specifico:
Quali sono le differenze principali tra reverse proxy e web server?Se il modello e il workspace sono configurati correttamente, AnythingLLM userà il provider impostato e il contesto del workspace per generare la risposta.
Nel mio caso, ho provato a caricare un PDF con informazioni su AWS, una overview generale. AnythingLLM mi ha chiesto di farne l’embedding, in quanto superava la context size window e così ho dovuto poi chiedere più esplicitamente a Qwen 3.5 di citare il materiale solo da quella fonte:
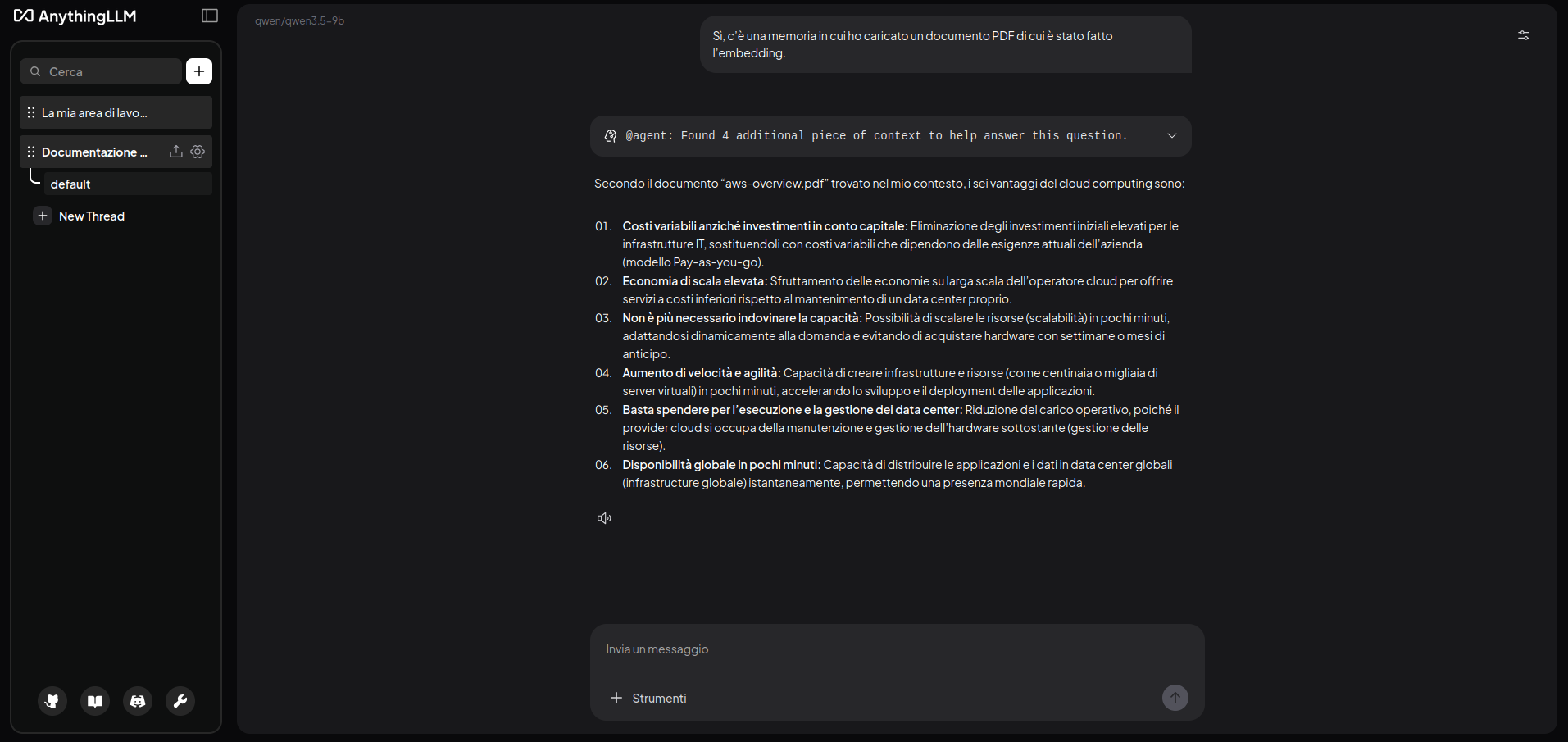
Ricerca web in tempo reale (stile Perplexity)
AnythingLLM supporta la possibilità di effettuare ricerche web per reperire dati aggiornati in tempo reale con vari servizi, tra cui SearXNG (il motore di ricerca self-hosted), DuckDuckGo e altri. Basta configurarli nelle impostazioni, come visibile qui:
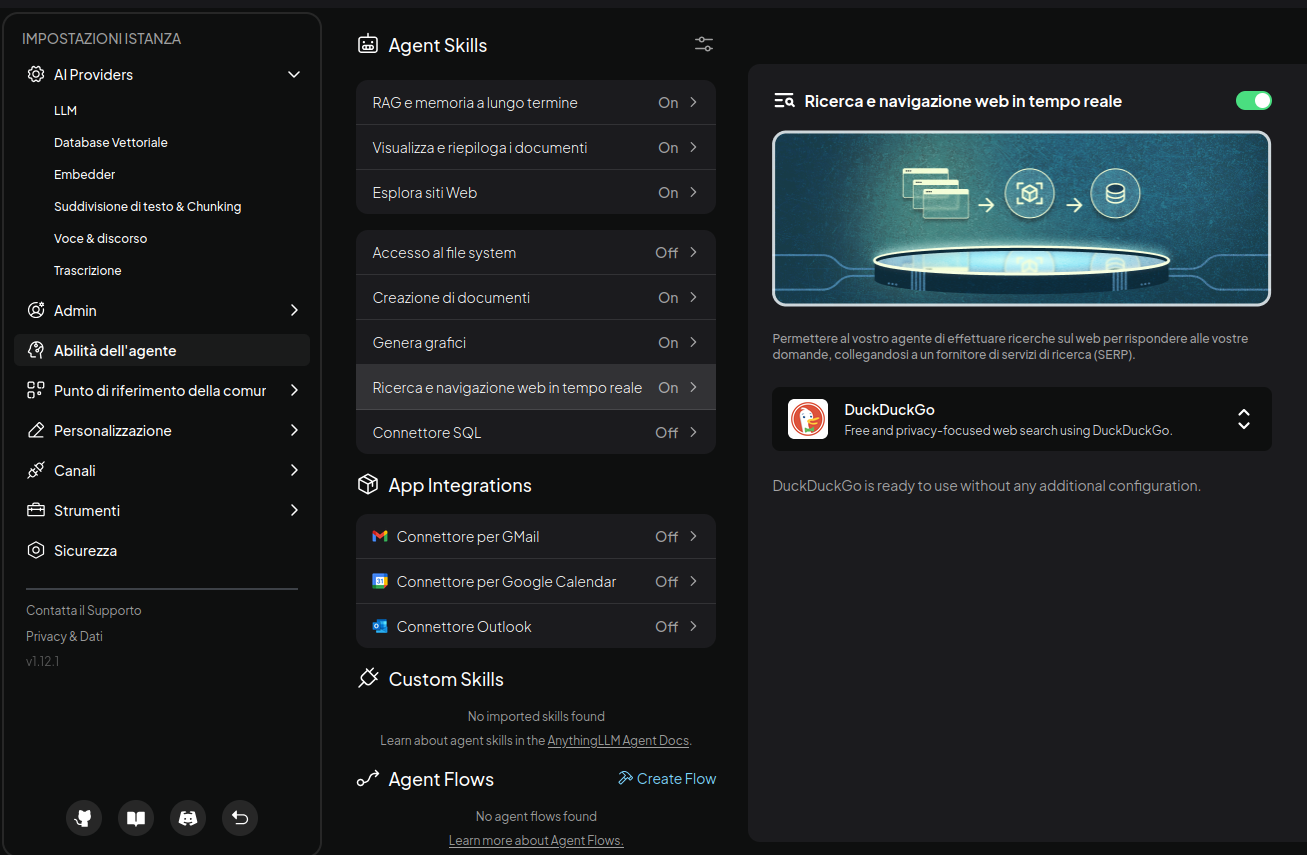
Installazione alternativa su Linux come app desktop
Se preferisci evitare Docker, AnythingLLM offre anche una applicazione desktop per Linux. La procedura usa uno script installer che scarica l’AppImage corretta per l’architettura del sistema:
curl -fsSL https://cdn.anythingllm.com/latest/installer.sh -o installer.sh
chmod +x installer.sh
./installer.shPotrebbe essere necessario creare una regola AppArmor, soprattutto se si sta usando Ubuntu o derivate, per evitare problemi legati al boot dell’AppImage. Nel caso, verrà richiesto direttamente in fase di installazione dallo script.
Problemi comuni
L’app non si apre su porta 3001
Controlla che il container sia realmente in esecuzione e che la porta 3001 non sia già occupata da altri servizi. L’accesso standard è su http://localhost:3001.
Dopo il riavvio ho perso tutto
Questo succede quasi sempre se il volume persistente non è configurato correttamente. Senza mount verso /app/server/storage i dati vanno persi al restart del container.
Problemi di permessi sui file
Controlla UID e GID, perché eventuali mismatch con i valori dell’host possono causare errori di accesso ai dati.
Il modello locale non risponde
Se usi un provider locale come Ollama o LM Studio, verifica che sia attivo e raggiungibile correttamente dal sistema dove gira AnythingLLM.
FAQ
AnythingLLM si può installare in locale con Docker?
Sì. L’installazione Docker locale usa l’accesso standard su http://localhost:3001.
Serve per forza un modello cloud?
No. AnythingLLM supporta anche provider LLM locali come Ollama, LM Studio, Local AI e KoboldCPP.
Posso usare modelli diversi per workspace diversi?
Sì. Esistono System LLM, Workspace LLM e Agent LLM, proprio per permettere configurazioni diverse nello stesso ambiente.
Considerazioni finali
AnythingLLM è una delle soluzioni self-hosted più interessanti per chi vuole costruire un ambiente AI locale con una curva di ingresso relativamente accessibile. Docker rende l’installazione rapida, mentre la gestione di workspace, modelli e documenti lo rende molto più utile di una semplice chat generica.
Il consiglio migliore è partire da un’installazione semplice con volume persistente, configurare un provider locale e creare un primo workspace piccolo. Una volta capito il flusso, puoi passare a casi d’uso più avanzati come documenti tecnici, knowledge base personali o agenti AI locali.
Per qualsiasi altra informazione in merito a AnythingLLM, ti consigliamo di visionare la documentazione del progetto, disponibile qui.